Attention is All I need: Transformer学习笔记¶
Attention is All you need 论文阅读笔记,该模型在翻译任务上表现良好。另外也是理解Attention的一个契机
总体架构¶
编码器和解码器各6层,共12层
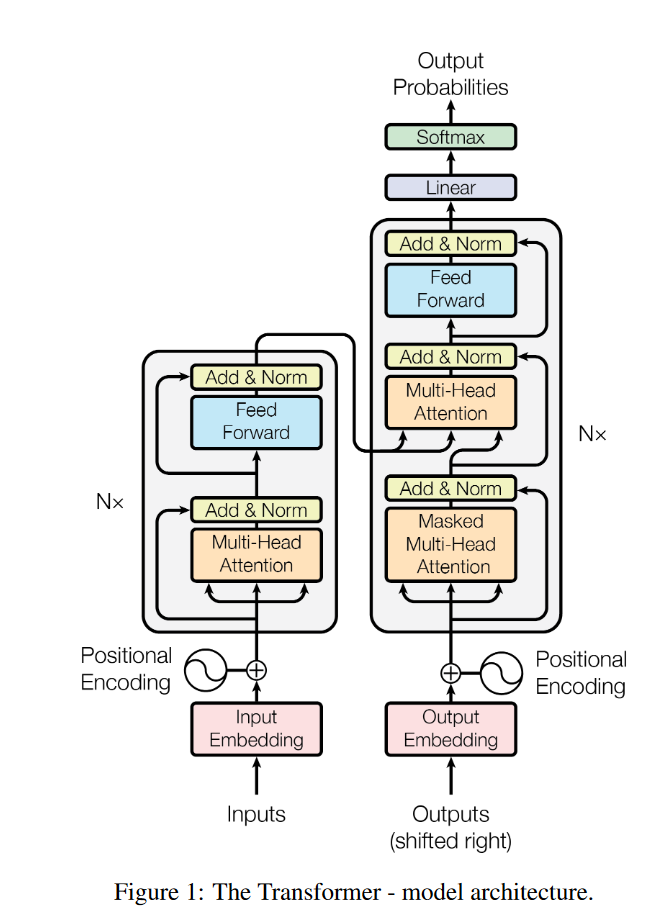
在每个Encoder结构中,首先经过Self-Attention
之后经过Feed Forward Neural Network
$FFN(Z)=max(0,ZW_1+b_1)W_2+b_2$
Decoder和Encoder类似,但是Output->SelfAttention->Encoder-Decoder Attention
- SelfAttention:当前翻译和已经翻译的前文之间的关系
- Encoder-Decoder Attention: 当前翻译和编码器输出(编码的特征向量)之间的关系
初级Encoder输入编码使用Word2vec的向量,其它层输入是上一层的输出
RNN的缺点¶
- 无法并行训练,需要有之前的结果才能有之后的结果
- 无法捕捉超长序列信息,虽然LSTM可以捕捉非常长序列的信息
Attention机制¶
来源于人类的注意力机制,即当面对大量信号时自动注意重点,然后才关注其它地方
在神经网络中,表现为给某个向量乘一个权值,凸显重要性
Self-Attention机制¶
即句子本身中的各个部分之间的注意力
$Z=softmax(\frac{QK^T}{\sqrt{d_k}})V$
输入是经过词嵌入的词向量$A=[a_1,a_2,...,a_n],a_i\in\mathbb R^m$
Attention机制中有三个可以训练的矩阵$W^Q,W^K,W^V$
$Q=AW^Q=[q_1,q_2,...,q_{n}],,K=AW^K=[k_1,k_2,...,k_{n}],V=AW^V=[v_1,v_2,...,v_n],W^Q,W^K,W^V\in\mathbb R^{m\times d_k}$
设$C=QK^T$,则$c_{ij}=q_ik_j^T$,以$c_1=[q_1k_1^T,q_1k_2^T,q_1k_3^T,...,q_1k_{n}^T]$为例,这里计算了查询$q_1$和各键值$k_i,i=1...n$的相对距离,经过softmax之后就变成了距离总数为1,各个向量到第一个向量的距离比重。最后除$\sqrt{d_k}$是因为当$c_ij$较大时softmax梯度较小,这样可以加速训练。经过这一步,得到的是一个$n\times n$的矩阵$G=[g_1,g_2,...,g_n]$
最后$z_{ij}=g_iv_j,$以$z_1=[g_1v_{11},g_1v_{21},g_1v_{31},...,g_1v_{n1}]$,以归一化的查询$q_1$到键$k_j$的距离作为权重,乘对应的向量$v_j$的第一个元素,即得到了最终第一个元素的表示,这就是其它向量的第一个元素对于$a_1$的第一个元素的注意力
例如商品购物(查询:作业本)时,每个物品都对应若干键(颜色、页数、厚度、种类,物品类目),每个物品本身也是一个值(条目)
利用查询和各个键进行比对,就可以知道每一个键和查询的距离,将相对距离和条目相乘,就得到条目的重要性。条目本身是有一些重要性的,例如淘宝会根据条目的评论之类的
换言之,键用于表示物品本身的特色,值用于表示物品本身的价值
在Transformer中,
- $W^K$就是键矩阵,用于提取那些可能和注意力有关的特征
- $W^Q$就是查询矩阵,用于将某个词转化为查询向量,例如买东西需要将实物转化为文字
- $W^V$就是价值矩阵,可以衡量某个词本身的价值
示例:
代码实现¶
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
权重矩阵$W^*$是利用全连接层表示的,表示注意力是可以学习的。在训练足够多的时间之后,翻译时就会让不同单词之间的注意力到一个合适的值
多头注意力(Multi head Attention)¶
以8头注意力为例
- 将$X$分别输入到8个SelfAttention中,得到$Z_1-Z_8$
- 将$Z_1-Z_8$拼接成一个大矩阵
- 经过一个全连接层输出得到Z
相当于集成学习,不同注意力层矩阵学到的注意力可能不同,集成一下减少误差
Encoder-Decoder Attention & Decoder Attention¶
Encoder-Decoder Attention中,Q来自于解码器的上一个输出,KV来自于编码器的输出
Decoder Attention中,当解码第k个向量时,只能看到k-1之前的结果,需要将之后的mask掉
损失函数¶
解码后,经过一层全连接层和softmax,得到每个单词的概率输出向量,之后就可以通过CTC等损失函数训练模型了
位置编码¶
$PE(pos,2i)=sin(\frac{pos}{1000\frac{2i}{d_{model}}})$
$PE(pos,2i+1)=cos(\frac{pos}{1000\frac{2i}{d_{model}}})$
$i$是单词维度,源码
这样设计是因为$sin(\alpha+\beta)和cos(\alpha+\beta)$都可以分解,也就是含有单词相对位置的信息,为捕捉相对位置提供方便
参考¶
https://www.bilibili.com/video/BV1nL4y1j7hA/
https://towardsdatascience.com/transformers-141e32e69591
https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://zhuanlan.zhihu.com/p/48508221
目前主流的attention方法都有哪些? - 张俊林的回答 - 知乎 https://www.zhihu.com/question/68482809/answer/264632289
https://web.stanford.edu/class/cs25/
http://web.stanford.edu/class/cs224n/
https://www.youtube.com/watch?v=0QgGIzElVNU
https://people.cs.umass.edu/~miyyer/cs685/
http://jalammar.github.io/illustrated-transformer/
https://zhuanlan.zhihu.com/p/105722023
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer