AI综述¶
目前主要是ML,后续添加
L1范式和L2范式¶
池化¶
池化是一种下采样,CV领域相当于缩小图片,多个点合成一个点。
优化函数¶
AdaGrad¶
AdaGrad是一组用于随机优化的次梯度算法。属于该家族的算法类似于二阶随机梯度下降和优化函数的Hessian近似。AdaGrad的名字来自自适应梯度。直观地说,它根据问题的估计几何形状调整每个特征的学习率;特别是,它倾向于将更高的学习率分配给不频繁的特征,这确保了参数更新更少地依赖频率,而更多地依赖相关性。

其中$g_t(x)$是$f_t(x)$的梯度
自监督学习¶
从没有标签的数据中学习。
- 基于伪标签初始化网络权重
- 实际任务通过监督或非监督学习进行。
自监督学习更类似于人类学习分类的方式。
- 对比学习:对比正例和反例,让正例之间尽可能相似,反例之间尽可能不相似
- 非对比学习:只有正例,学习如何分类正例
注意力负采样,课程学习
参考¶
https://optimization.cbe.cornell.edu/index.php?title=Main_Page
损失函数¶
Ranking Loss¶
是度量学习,用于预测输入样本之间的相对距离。
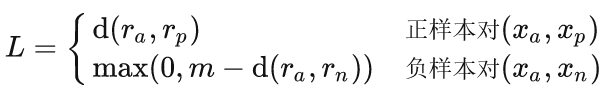
$x_a$是锚点样本,正样本对两个样本距离尽可能小,负样本对的距离应该大于某个阈值$m$,$r_a,r_p,r_n$是这些样本的特征表示
损失函数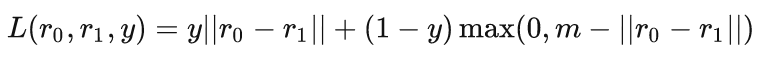
三元组类型的Randing Loss是正负样本比较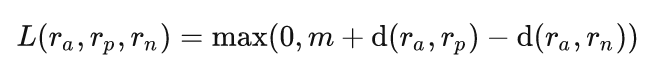
Cross-Entropy Loss¶
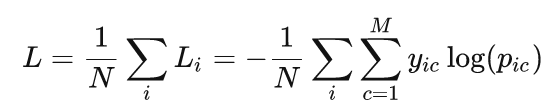
$M$--类别的数量
$y_{ci}$--如果样本i的真实标签等于i则为1,否则为0
$p_{ci}$--观测样本i属于类别c的概率
参考¶
https://zhuanlan.zhihu.com/p/158853633
Frobenius product¶
$A:B=\sum\limits_{i,j}A_{ij}B_{ij}$