ParmeSan: Sanitizer-guided Greybox Fuzzing¶
https://www.usenix.org/system/files/sec20-osterlund.pdf
fuzzing中的一个重要问题就是去哪里找漏洞。代码覆盖率会希望覆盖更多的代码以找到更多bug,将bug覆盖率太过近似于代码覆盖率了,可能找到bug需要更多时间(TTE)。导向fuzz尝试将fuzzer导向到可能出现bug的地方,减少特定bug的TEE,但是这种fuzzer又不够近似于bug覆盖率。
本文提出了sanitizer导向的fuzz,专门针对bug覆盖率进行了优化。作者观察到,现有的Santizer插桩通常被用于检测fuzzer引起的错误条件,这种机制可以被用于识别感兴趣的基本块,来引导fuzzer。基于这个实现了ParmeSan,可以减少TEE,比最快的基于覆盖率的fuzzer(Angora)快37%,比基于导向导向fuzzer(AFLGo)快288%,并且可以找到相同的bug集合。
Motivation¶
代码覆盖率fuzz期望覆盖更多代码以找到更多漏洞,但是实际上大量时间都花在了不包含bug的代码上。导向fuzz又会导致bug覆盖率不足。
Methodology¶
作者观察了编译器Sanitizer--在目标程序中插入检测可能bug代码的错误检测框架,可以利用这一机制提升目标程序的bug覆盖率。通过引导fuzz过程向触发sanitizer检查的方向进行,可以触发和代码覆盖率同样的bug但是只需要较少的代码覆盖率,从而减少bug发现时间。另外由于llvm支持多种sanitizer,还可以只是选择一部分bug,只需要选择对应的sanitizer即可。
本文提出了ParmeSan,依赖于现有的sanitizer机制最大化某一类型的bug覆盖率,可以比已有的解决方案花更少的时间找到特定bug。ParmeSan不限制于特定API或特定区域,但是目标是找到bug。不期望覆盖所有基本块,而是引导执行流程和执行路径,在最少时间找到触发bug的尽可能多的机会。
挑战以及解决方案:
- 从一个给定的sanitizer中自动化提取感兴趣区域:把程序中的sanitizer插桩版本和基线比较,在黑盒中定位sanitizer检测部分,利用剪枝策略过滤掉不感兴趣的区域。
- 自动化精确构建跨过程的控制流图(CFG),用于引导fuzzer到目标区域。由于静态的构建方法不够精确,本文使用一种动态的构建方法。
- 在以上两种方案上构建一个fuzzer。使用两阶段fuzz策略(CFG构建fuzz和目标点fuzz),以及两阶段的协同。
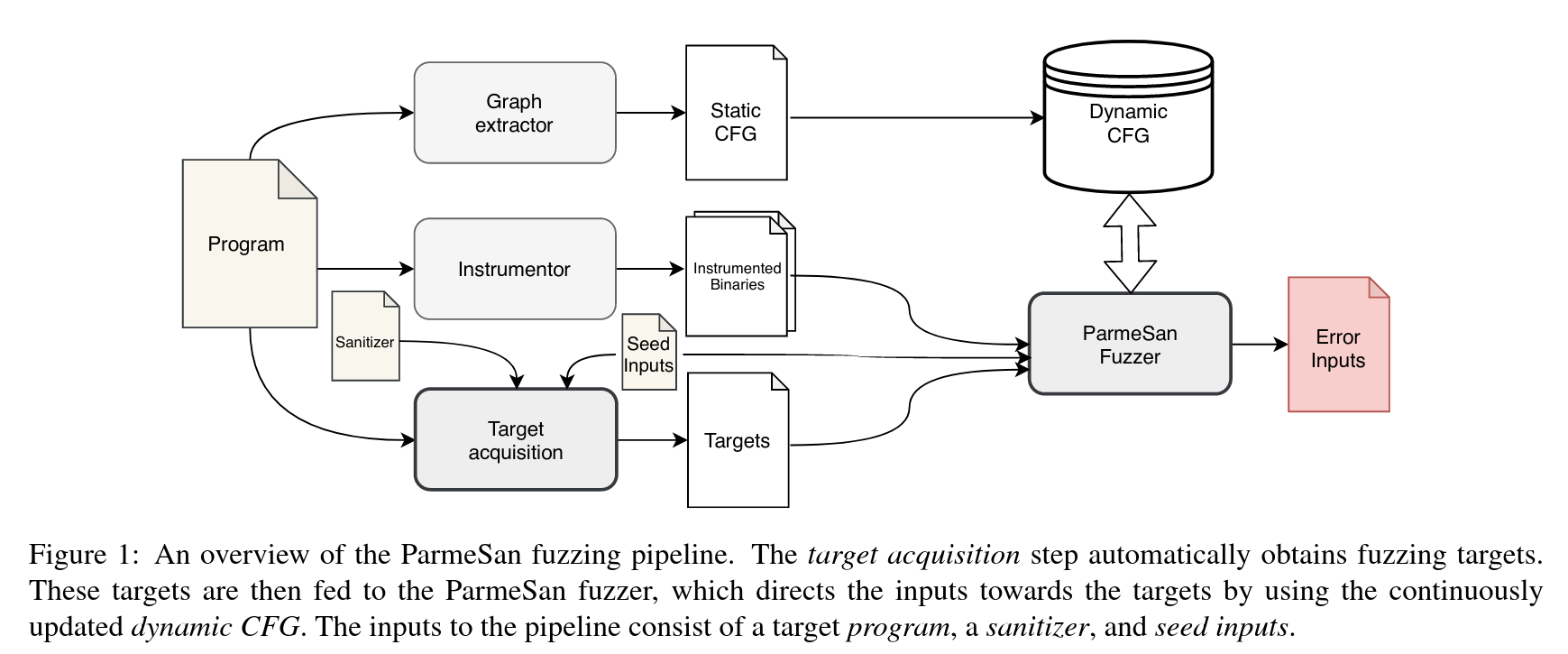
动态CFG组件:包含一个用于多目标fuzz的精确、输入感知动态CFG。当发现边的时候会向CFG种添加边,依赖于数据流分析DFA跟踪输入和CFG的依赖。从而动态CFG组件可以跟踪输入相关的CFG变化,提供哪个位的变化引起了CFG变化。
Fuzzer组件:输入是插桩后的二进制文件,目标集合,初始距离,种子集合。
- 首先利用种子获得一个初始基本块集合,以及到达这些基本块的条件
- 尝试引导执行到目标,目标是从目标获取组件得到的,距离等相关信息由CFG组件提供。
- 每一轮尝试,fuzzer会优先解决到达目标基本块的最佳距离和最佳条件,这些条件从访问过的条件列表中获得
- 还需要使用DFA为CFG计算约束,DFA不仅用于找到目标地址的新代码,而且用于到达目标sanitizer检查来触发bug
输出包含可以触发错误的输入
贡献¶
- 演示了一种通过已有sanitizer找到感兴趣区域的通用方法
- 描述了一种用于引导输入到目标CFG的精确动态构建方法
- 实现了ParmeSan,使用sanitizer导向的fuzz策略,高效到达感兴趣的区域
- 评估了ParmeSan,展示和最先进的覆盖率导向fuzzer和导向fuzzer相比,找到同样的bug需要更少时间