Prevalence and Impact of Low-Entropy Packing Schemes in the Malware Ecosystem¶
https://www.ndss-symposium.org/wp-content/uploads/2020/02/24297-paper.pdf
恶意软件分析中一个开放式的问题就是如何静态区分加壳恶意软件和未加壳恶意软件,如果成功区分,就可以让反病毒软件对加壳恶意软件使用消耗计算资源更多的动态分析方法。在研究中也很有用,因为很多研究者设计的算法可能针对加壳或不加壳的恶意软件。
熵和加壳有联系,导致一个错误假设就是低熵表示没有加壳。这种原则的例外也有,但是被考虑成个例。本文的研究指出,有许多实现了特定模式的加壳恶意软件也可以保持低熵。本文分析了50K个Windows低熵恶意软件,其中30%有运行时加壳。然后延伸研究到纯熵之外,考虑所有静态特征,结果显示即使最先进的ML方法也无法利用静态分析判断一个低熵恶意软件是否加壳。
Motivation¶
恶意软件的具体加壳比例还不清楚,相关研究指出,58%的恶意软件使用现成的壳,35%的加壳恶意软件使用自己写的壳(这个研究的作者使用基于签名的检测方法,会产生很多假阳性)。但是很多技术例如静态分析,聚类,二进制相似度都无法提供好的结果。导致研究者不得不使用动态脱壳方法,消耗大量时间和计算资源,或者基于动态分析使用更有弹性的静态分析解决方案。
一个错误的分类也会导致数据集的污染,研究者通常依赖于同时包含加壳和未加壳的恶意软件数据集,这种错误会导致很难产生可信可靠的结果。
研究问题¶
本文的研究目标是展示在大多数情况下加壳和高熵不是$\approx$,并通过回答以下问题提高低熵加壳知识
- 哪种方法和加壳技术被现实中的恶意软件使用,来降低熵
- 低熵加壳技术有多广泛?当设计恶意软件实验时,低熵加壳技术是否是一个需要考虑的因素?
由于有些方案还使用了其他静态特征,还需要回答以下问题
- 已有的静态分析解决方案能否区分低熵加壳恶意软件
- 如果不能,能否结合所有的静态分析特征实现,或者说该领域需要新的研究
一些低熵加壳方法¶
- 字节填充:通过填充低熵字节减少总体熵值
- 编码:使用不同的编码表示加壳后的数据以便减少熵
- 单字母替换
- 转换:混合一些字节以重构代码
- 多表替换
方法¶
整理了50000个低熵恶意软件样本,来自多个家族。开发一个动态分析工具来分来每一个样本并归类低熵加壳方法
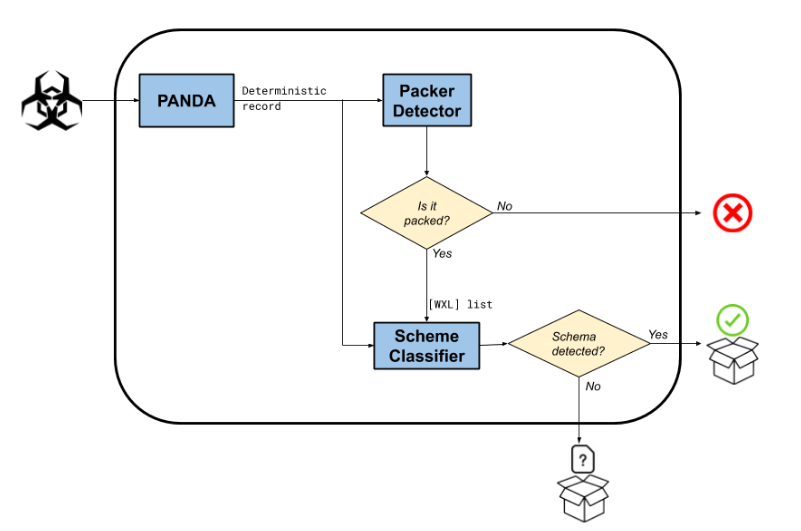
其中Scheme Classifier基于如下事实
- 定位包含低熵加壳数据
- 操作这些数据
- 将脱壳数据写入到目标缓存
结果¶
30%的实验样本有运行时加壳行为。
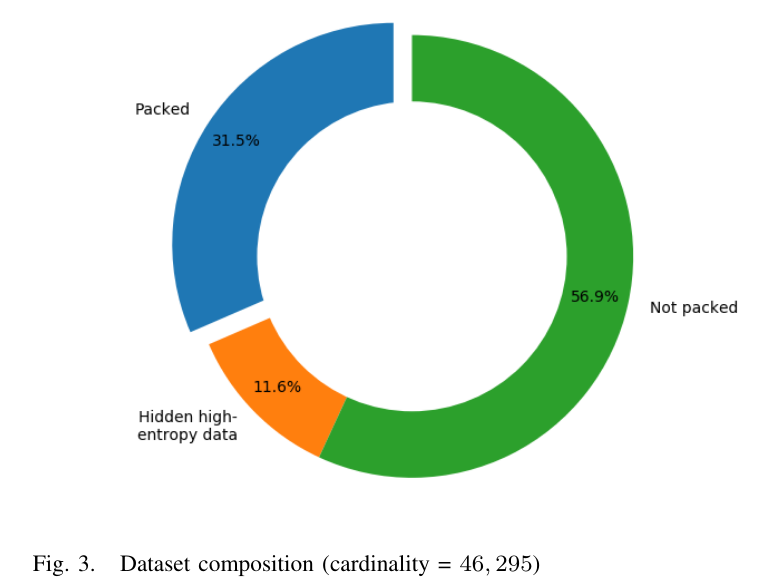
低熵加壳方法分布