TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time¶
Android恶意软件分类已经达到了0.99准确度,本文认为结果不准确,由于两个不可避免的实验偏差来源:训练和测试集的分布不代表真实世界的情况;训练和测试集不正确的时间分割导致时间偏差,导致了不可能的配置。我们提出了一系列空间和时间约束,用于实验设计,消除两种偏差。本文介绍了一种新的指标,可以概括一个分类器在现实世界可能达到的鲁棒性,和一个微调性能的算法。最后演示了这个算法如何评估时间衰减的缓解策略,例如主动学习。作者在TESSERACT中实现了该解决方案,作为一个开源的框架,可以在现实世界设置下比较恶意软件分类器。作者使用TESSERACT评估了三个Android恶意软件分类器,使用129K个三年中的数据集,评估结果验证了公布的结果是有偏差的,以及适当的微调是可以带来很大提升的。
Motivation¶
恶意软件是动态的,因为总会出现新的家族和变种,预测质量也随之下降。因此,时间一致性会影响分类器的评估。当实验允许分类器训练未来知识时,这种报告结果就会有偏差。
本文认为Android恶意软件分类器并没有使用现实世界的环境设置评估。选择Android是因为公共可用性、大规模和有时间戳的数据集,以及可以方便复现的算法。
Design¶
在两个维度识别实验偏差:时间和空间。空间偏差指关于数据集中良性软件和恶意软件比率不现实的假设。良性软件和恶意软件的比率是依领域而定的,但是在测试时必须模仿现实世界场景下的比率。时间偏差指训练集中集成了关于测试对象未来知识或不显示的设置。这种情况在家族相关的恶意软件中更为严重,只要训练集中有某个家族中的一个恶意软件出现,分类器就可以识别测试集中该家族中很多变种。
这些问题主要由于两个原因:评估偏差可能的来源是非公共的知识;考虑到时间会使评估复杂化,并且不允许使用F1分数和AUROC等主要指标和其它方法比较。
数据集使用AndroZoo
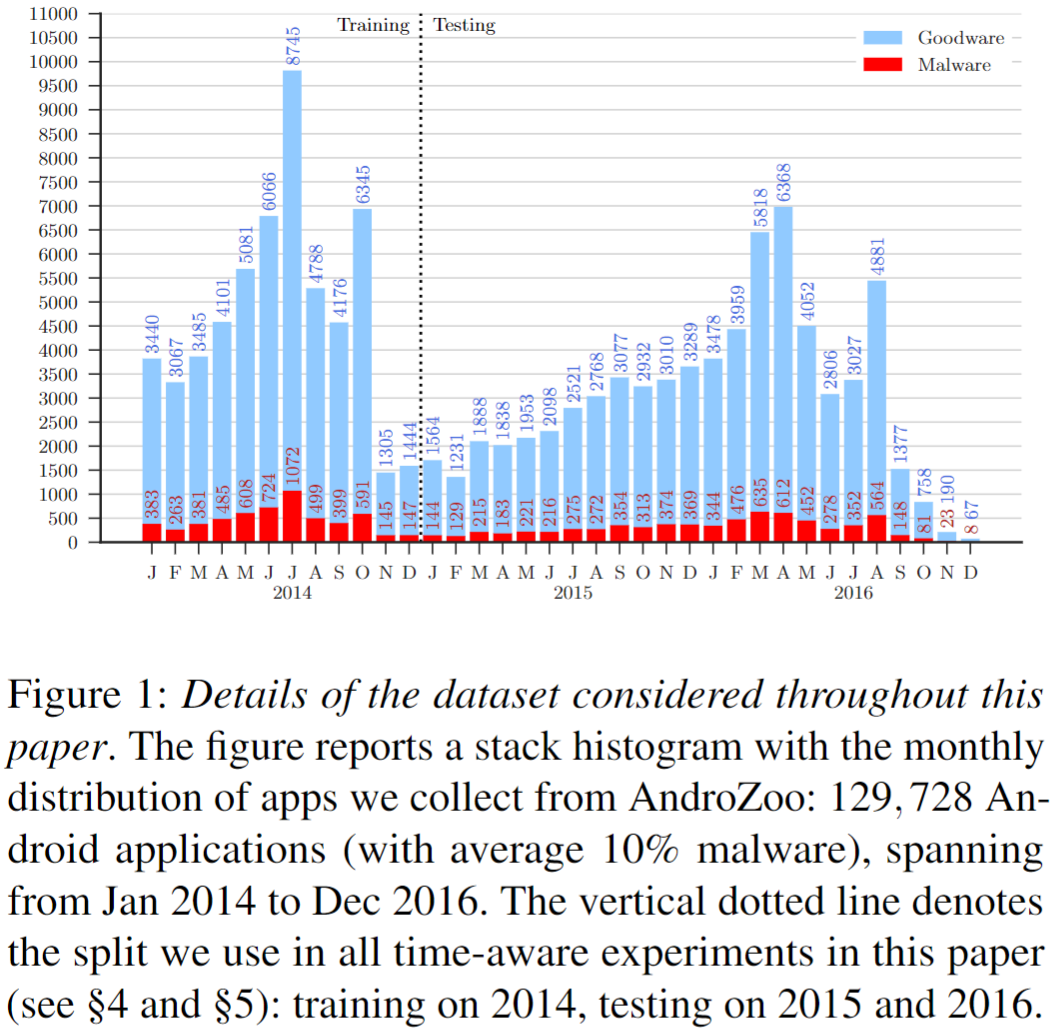
由于时间和空间偏差影响的结果
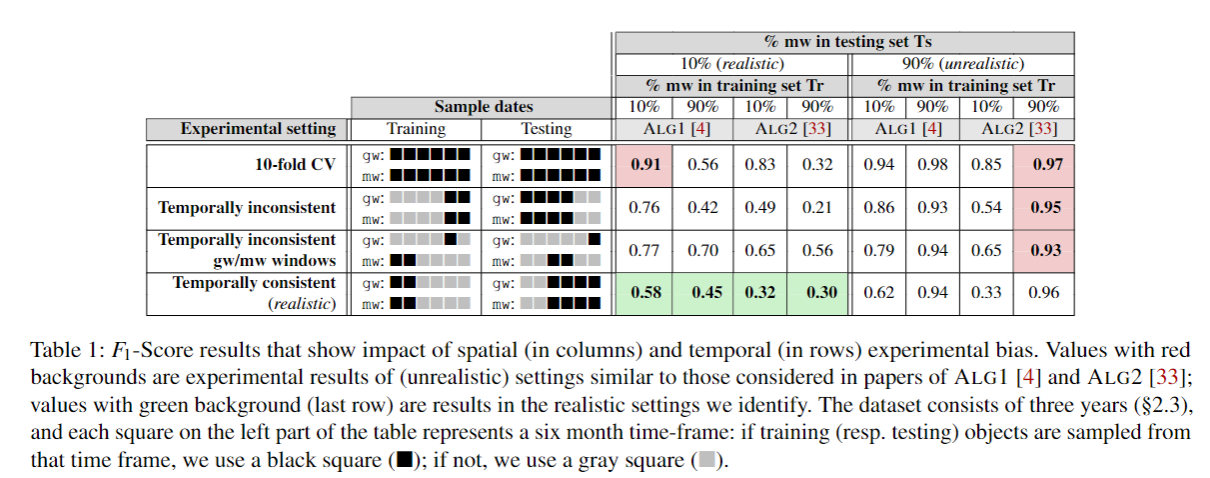
空间-时间感知评估¶
需要有三个一致性约束
- 训练中的所有对象出现的时间都应该比测试集中早
- 在每个测试时间窗口S中,所有的对象都应该来自于同一个时间窗口,训练集也应该一致。如果违反,会导致分类器在人为行为上学习和测试
- 测试集中的良性-恶意软件符合现实比率
时间感知评估指标¶
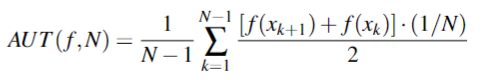
允许在现实世界设置下的N个时间单元中评估性能
利用AUT微调训练比率¶
设训练比率为$\varphi$,则优化算法解决如下问题
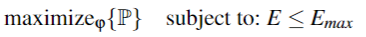
$E$是错误率,P是性能,包括F1分数,精度和召回率,如下计算
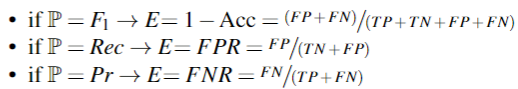

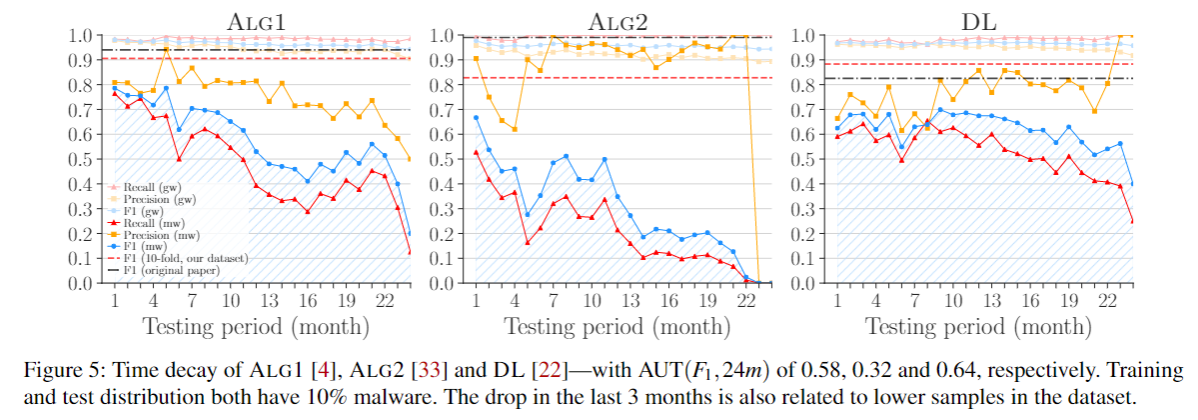
Result¶
AUT评估的曲线
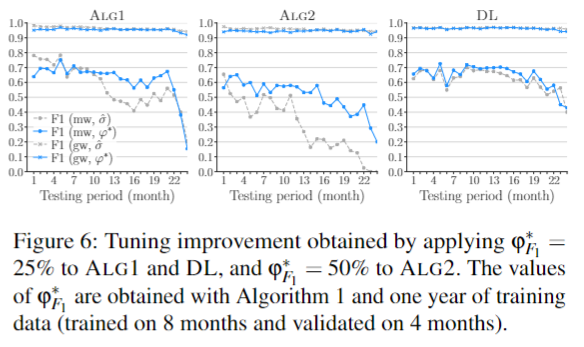
微调之后的性能提升
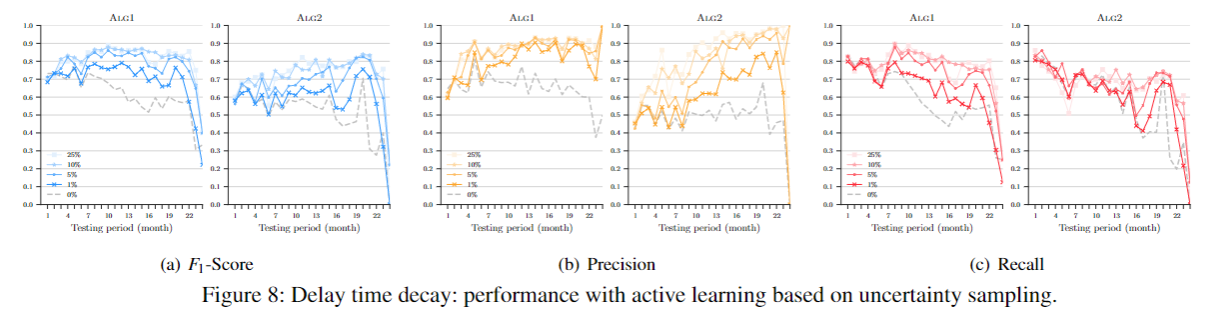
贡献¶
- 识别了不正确的训练集-测试集分割导致的时间偏差,和关于数据集分布不现实的假设导致的空间偏差。评估了129K个应用,由于偏差,两个知名分类器(DREBIN, MAMADROID)(ALG1,ALG2)性能最多下降到了50%
- 提出了一种新的鲁棒的评估恶意软件方法:在实验中强制设置一系列空间-时间约束;一种新的指标,AUT,可以获取分类器对于时间衰减的鲁棒性并且允许不同算法的公平比较;一种新的微调算法,在分类器代表少数类别的情况下,可以优化分类器的性能。比较了ALG1,ALG2和另一个算法DL,展示了移除偏差能够提供很好的性能。
- 实现并且公布了代码TESSERACT,描述了研究如何被应用到解决方案的评估性能损耗权衡,来缓解时间衰减,例如主动学习。