How Machine Learning Is Solving the Binary Function Similarity Problem¶
https://www.usenix.org/system/files/sec22fall_marcelli.pdf
二进制片段相似度的比较在安全、编程语言分析和ML领域都起到了很重要的作用。但是这个领域有研究结果的再现性和不透明性的问题,阻碍了有价值和有意义的结果出现
本篇论文对该领域的前沿进行了评测。首先将研究领域系统化,然后识别相关研究,实现了最近提出的代表性的研究,并且创建了一个数据集。
介绍¶
二进制相似问题即:输入一个函数的两个二进制表示,输出一个数字表示两个表示两个表示的相似度。这个问题很难,因为二进制表示的来源受到语言、编译器及其选项甚至架构的影响。
二进制相似度比对在现实生活中很重要,例如逆向工程中命名strip之后的静态链接库函数。还可以匹配和检测第三方库的漏洞。在软件沿袭分析和恶意软件聚类中也有应用。
这个领域的人期望回答以下问题
- 当使用相同的数据集和相同指标时,不同的方法比较结果如何
- 和简单的模糊哈系法相比,新的基于ML的方法主要贡献是什么
- 不同特征集的作用是什么
- 不同的方法在不同任务上工作得更好吗
- 跨架构比对比同架构比对更难吗
- 是否有任何新的研究方向看起来更有希望作为设计新技术的未来方向
为了回答这些问题,有如下挑战
- 无法复现之前的结果。只有少量研究者发布了他们的源码,但是由于缺少核心组件,解决方案描述不够准确,复现的结果也经常不对
- 评估结果常常是不透明的。因为比较的对象不同(漏洞发现或恶意软件归类),环境不同(架构或编译器),指标不同(ROC或top-n或MRR10),很多论文中的图像是无法比较的。一些论文还会忽略函数选择方法和如何选择函数对进行训练,即使在同一二进制数据集上也很难产生令人信服的结果
- 相关工具的使用。控制流提取,反编译器的使用等
- 由于前两点,无法知道二进制相似度研究中,哪个方向是领头,为什么。
本文的贡献如下
- 复现和比较了几种解决方案
- 提出了一个作为基准的数据集
- 发布了复现代码、详细使用文档,复现结果 https://github.com/Cisco-Talos/binary_function_similarity
选择的方法¶
选择的标准¶
- 可扩展性和现实世界可用性
- 有代表性的方法而不是特定的论文
- 覆盖不同的研究领域
- 优先选择最新的
选择的方法¶
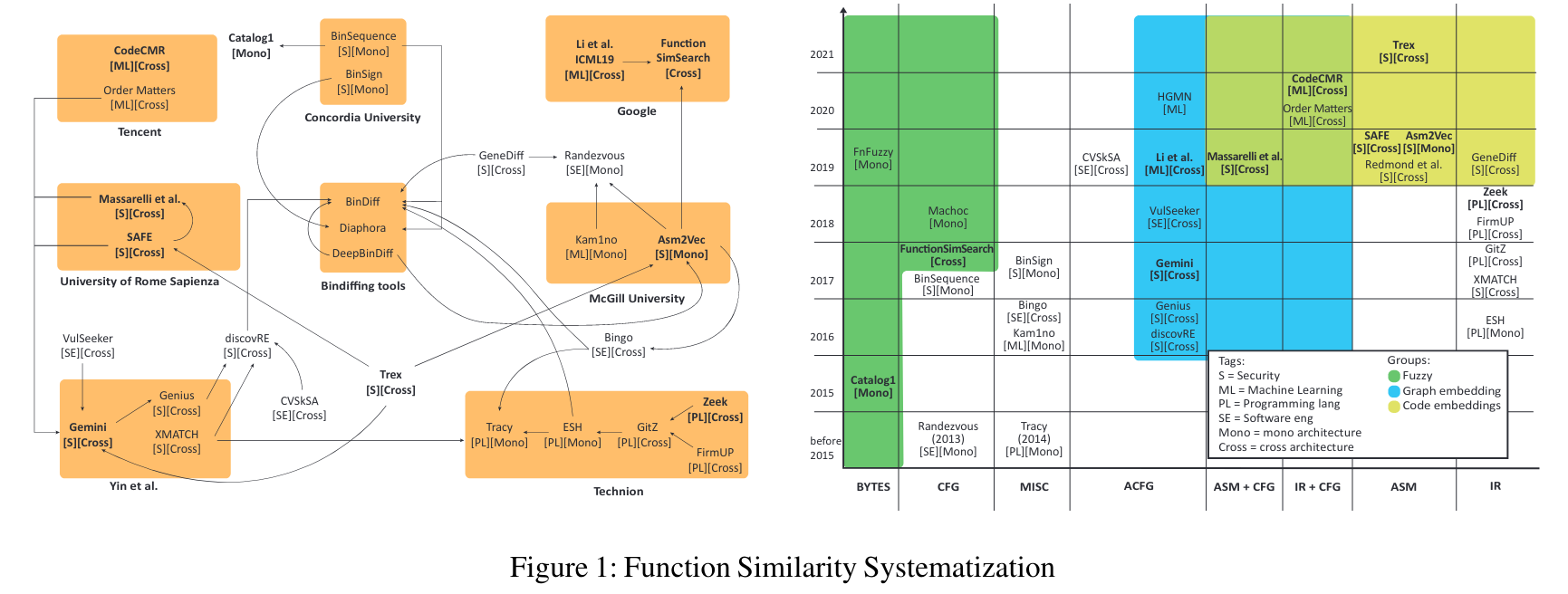
- 字节模糊哈希:Catalog1
- CFG模糊哈希:FunctionSimSearch
- 带有属性的CFG和GNN:Gemini
- 带有属性的CFG, GNN和GMN:Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. Graph matching networks for learning the similarity of graph structured objects
- IR,数据流分析和神经网络:Zeek
- 汇编代码嵌入:Asm2Vec
- 汇编代码嵌入和自注意力编码:SAFE
- 汇编代码迁入,CFG和GNN:Luca Massarelli, Giuseppe A. Di Luna, Fabio Petroni, Leonardo Querzoni, and Roberto Baldoni. Investigating Graph Embedding Neural Networks with Unsupervised Features Extraction for Binary Analysis
- CodeCMR/BinaryAI.
- Trex
评估¶
数据集¶
有两个数据集
- ClamAV, Curl, Nmap, OpenSSL, Unrar, Z3, and Zlib且包含所有的2015-2021的发布版本,包含x86-64, ARM, MIPS架构,5个优化级别O0, O1, O2, O3, Os
- 基于Terx中的数据集制作,Binutils, Coreutils, Diffutils, Findutils, GMP, ImageMagick, Libmicrohttpd, LibTomCrypt, PuTTy, SQLite. 4个架构x86, x64, ARM 32 bit,MIPS 32 bit, 4个优化级别O0, O1, O2, O3,使用GCC7.5编译,用于使用更大的数据集验证数据集1中的模型,并且和Terx比较
指标¶
- XO:不同优化级别,但是相同编译器和架构
- XC:不同优化级别、编译器、版本,相同架构和位数
- XC+XB:不同编译器、版本、优化、位数,相同架构
- XA:不同架构和位数,相同编译器、版本、优化
- XA+XO:不同架构、位数、优化,相同版本
- XM:任意架构、版本、位数、编译器、优化
结果¶
模糊哈希法
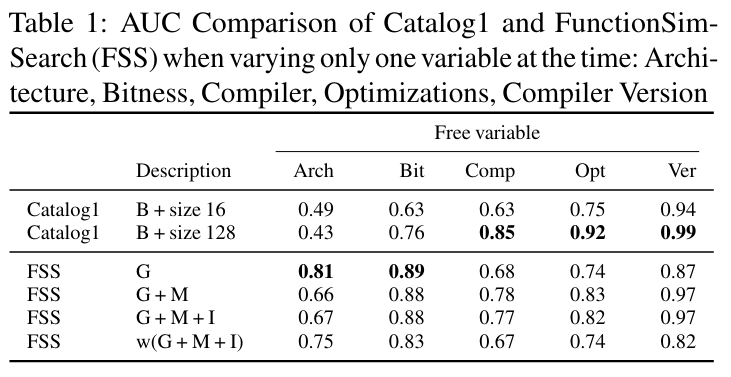
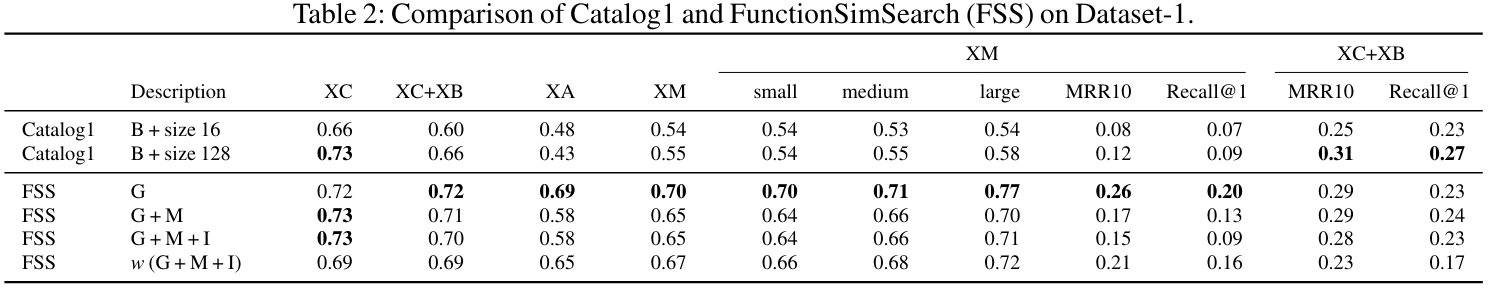
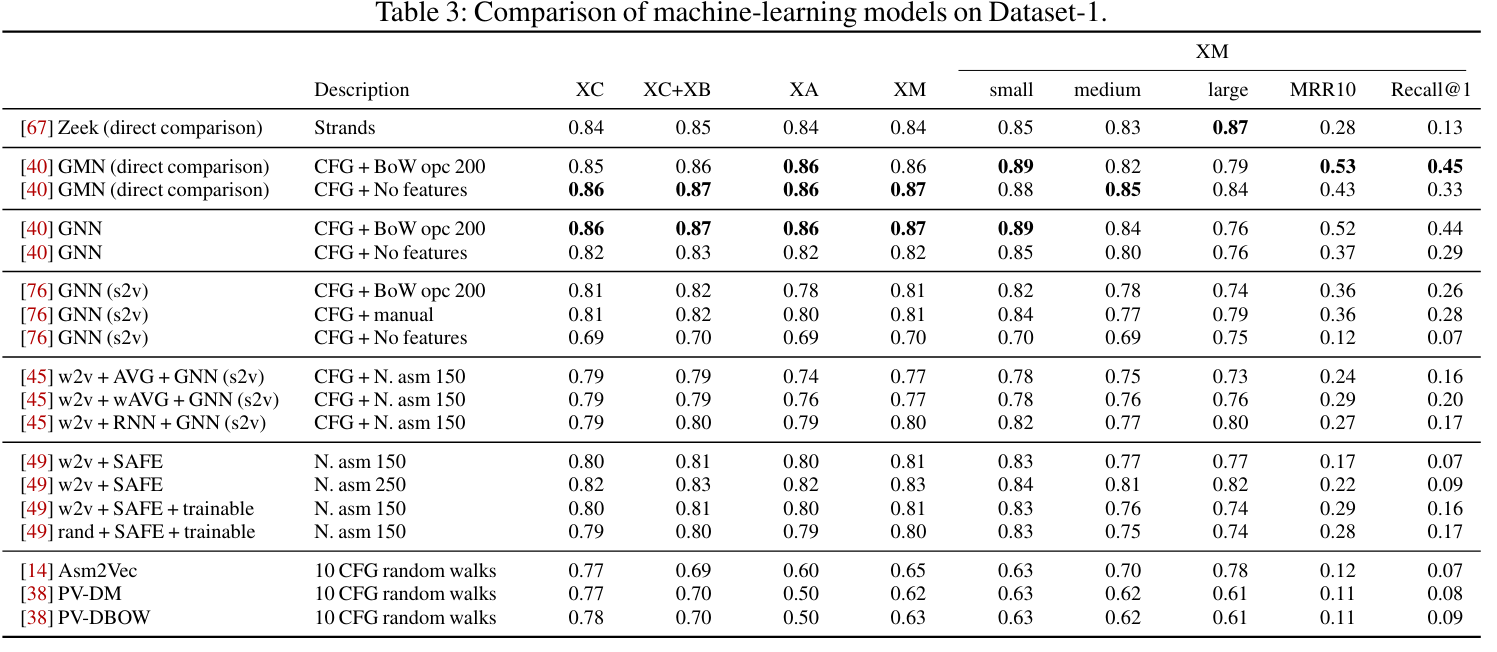
机器学习模型比较
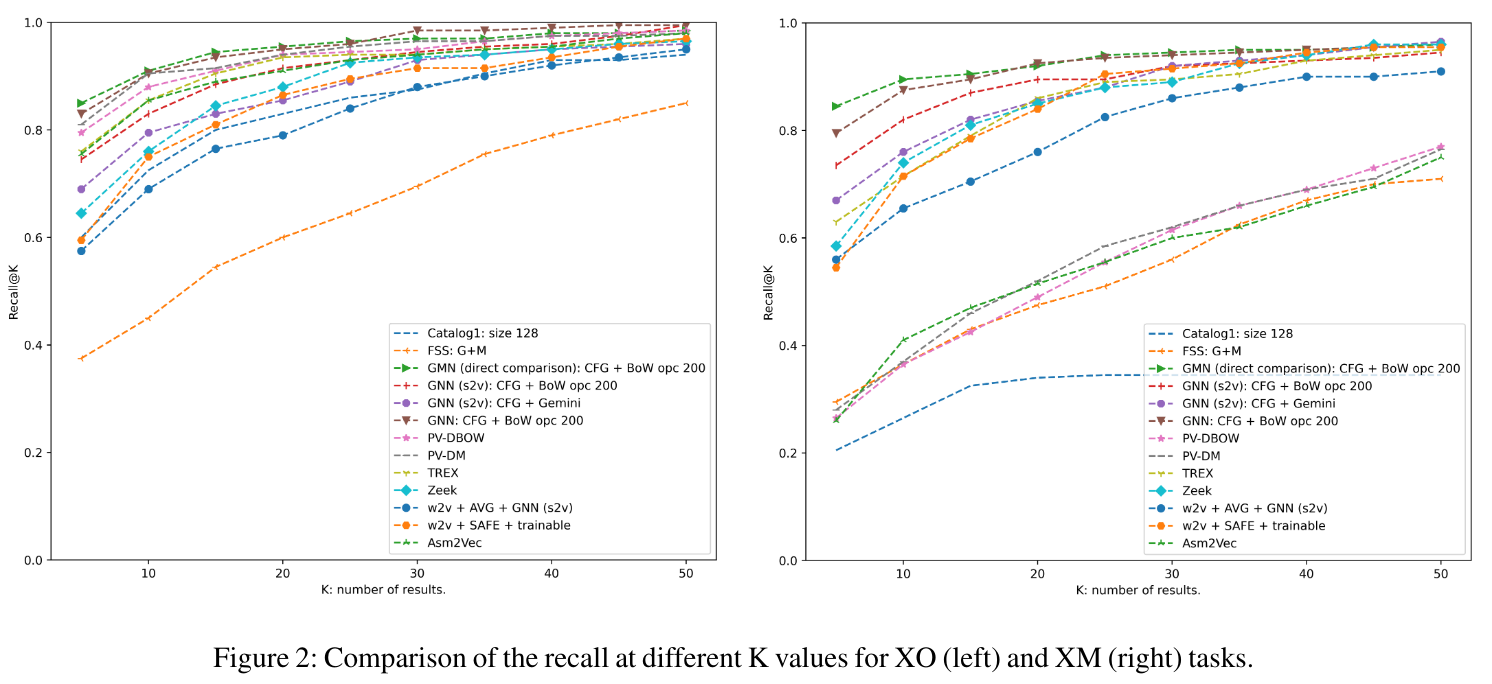
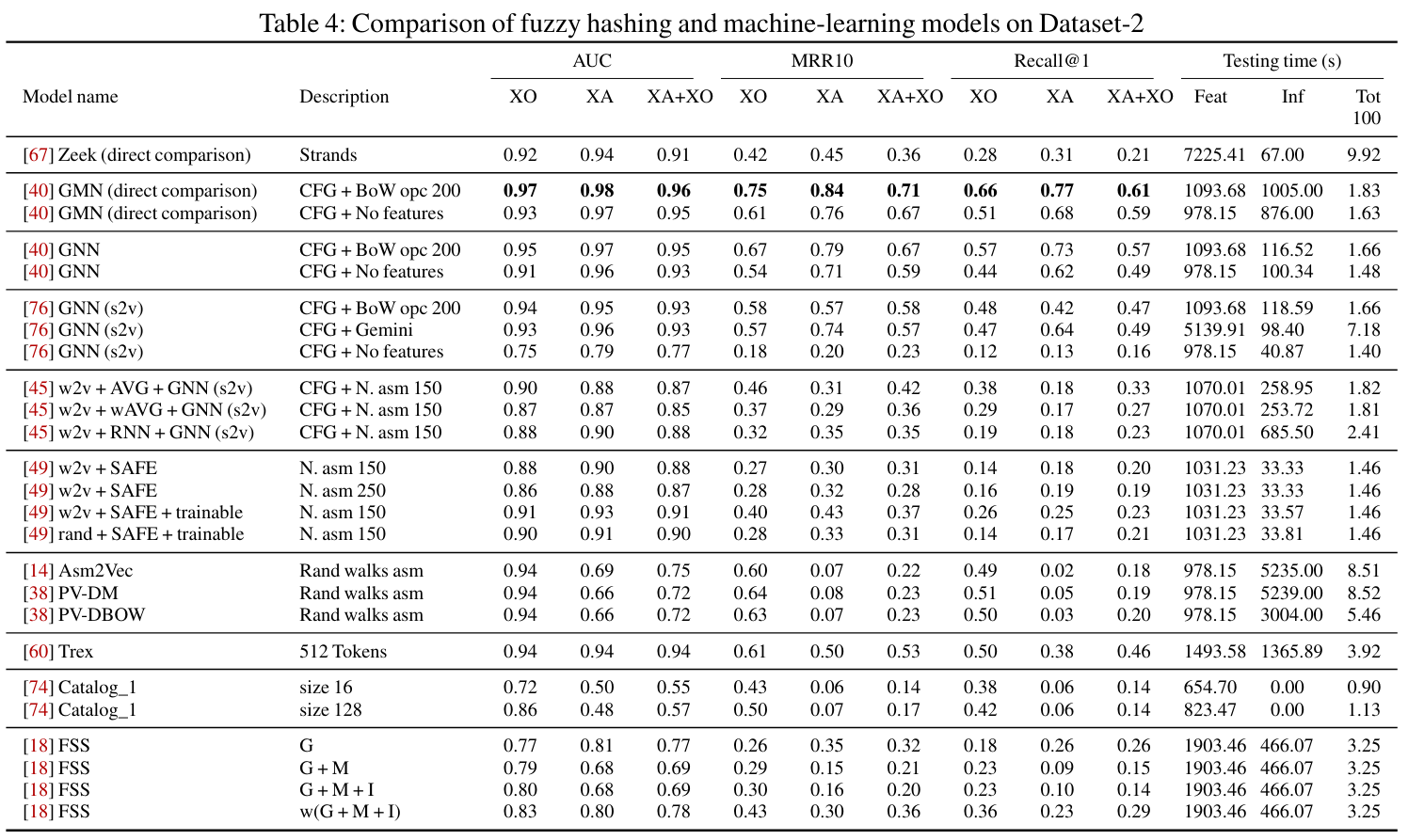

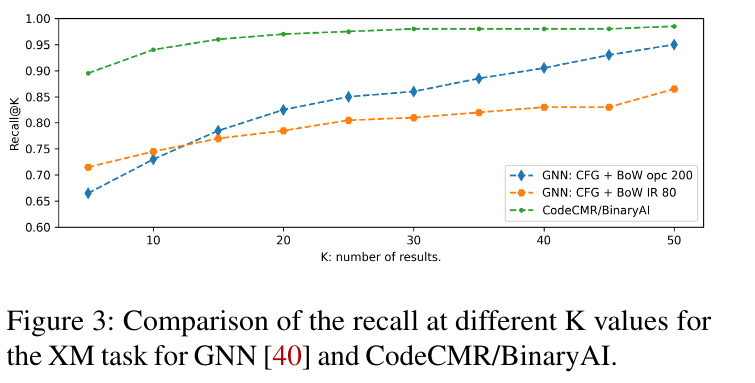
讨论¶
Yujia Li, Chenjie Gu, Thomas Dullien, Oriol Vinyals, and Pushmeet Kohli. Graph matching networks for learning the similarity of graph structured object 超过了其它方案,Asm2Vec未超过其它任何一个方案
ML在二进制比对中的主要贡献是在不同类别之间强制添加空间隔离。
ML方法在不同任务上性能相似
基于深度学习、GNN+汇编语言编码是有前景的方向