YarIx: Scalable YARA-based Malware Intelligence¶
https://www.usenix.org/system/files/sec21-brengel.pdf
YARA是一种在恶意软件数据集中搜索特定模式的工业标准,恶意软件分析非常依赖这种YARA规则,用于识别特定的威胁。YARA分析恶意软件是很有用,但是运行时间随输入文件量线性增长,导致在大数据集中表现不佳。
本文提出了YARIX,利用n-gram方法,可以通过查询n-gram的方式加速文件的查找,并且通过变长编码压缩n-gram以减少存储空间
Motivation¶
YARA是一种用于表达恶意软件中特定patten的社区和工业标准,一个YARA规则可以确定一个恶意软件是否符合特定的模式,这个模式可能来自于已知恶意软件,从而确定恶意软件家族。YARA规则也是威胁情报的一部分,YARA库也在日益增长,以适应日益增长的恶意软件数量。
但是日益增长的恶意软件数量对于YARA用户来说也是一个挑战,YARA在小数据集上表现不错,但是无法扩展到大数据集。例如使用YARA探测一个32M的恶意软件数据集会花上几天的时间。这就导致无法满足恶意软件分析人员的需求。
恶意软件分析人员的需求如下
让YARA适应大型数据集
在大型数据集中快速搜索已知规则
应用和临时微调YARA签名,用于快速发现已知的紧急威胁
Methodology¶
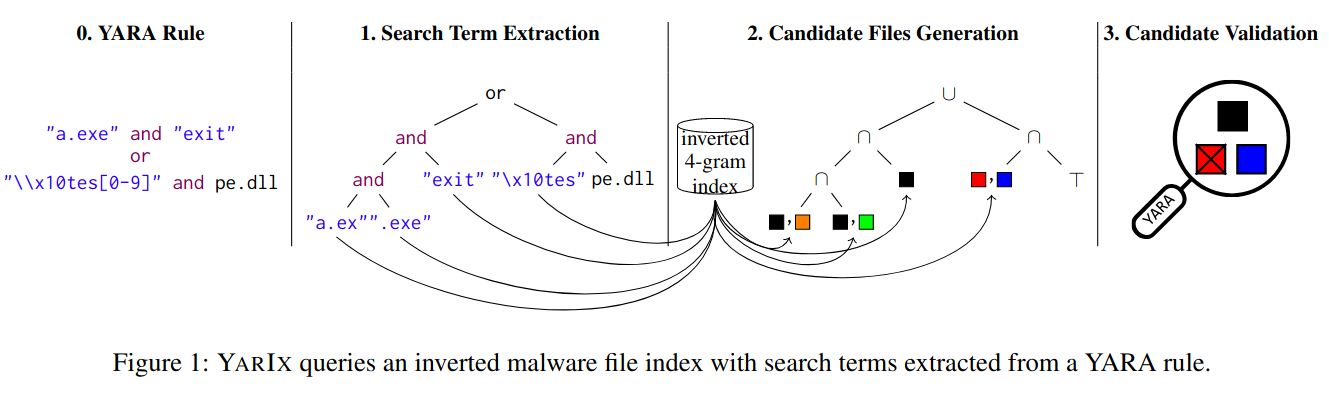
本文提出了YARIX搜索引擎,具有速度和存储优势,主要思路如下
利用YARA规则建立一个反向n-gram索引
将YARA规则转化为利用n-gram快速搜索条目
解析YARA规则并且提取出所有满足规则的n-gram串
使用n-gram索引以实现亚线性复杂度搜索
索引和YARA独立,有新的YARA规则时无需更新索引。并且YARIX支持YARA高级功能。例如正则表达式或库导入。
YARA还保证了完整性和健全性。通过精确转化YARA规则保证完整性。为了保证健全性,YARA会在扫描反向索引时返回所有满足要求的候选文件,是实际满足要求文件的超集,这样也就减少了需要扫描的文件。
如果使用n-gram,反向索引会占用$2^{8n}$位的存储空间,为了减少反向索引的存储空间,YARA采用如下方式
使用变长编码
使用增量编码压缩发布列表
提出了一种过度近似的基于分组的压缩方法
分组基本思路如下:我们将发布列表中的每个文件ID随机分配给一个组,并存储一个组ID而不是文件ID。 存储组 ID 而不是文件 ID 会带来两个优化好处。 首先,通过选择足够小的可能的组数,它进一步减少了占用空间,因为即使在未压缩的形式下,存储组 ID 需要的位也比文件 ID 少。 其次,从文件 ID 到组 ID 的随机映射会产生冲突,因为发布列表中的多个文件 ID 可能属于同一个组,因此也节省了空间。
结果¶
作者在一个32M的恶意软件数据集上尝试了4-gram索引。
压缩方法将400%的存储开销降低到了149.5%,分组方法又将数据量减少到了74%。
YARIX减少了搜索时间,尝试了1404个YARA规则,时间减少了5个数量级。
贡献¶
提出了YARIX,可以利用反向索引进行高效搜索
提出了一种全自动的方法,可以将已有的YARA规则转化为YARIX规则,并且转换结果是健壮完整的
评估了压缩方法的效率
在32M的数据集和1404个规则上测试了原型工具,发现时间减少了5个数量级