You Are What You Do: Hunting Stealthy Malware via Data Provenance Analysis¶
传统的检测技术很难检测隐形恶意软件(使用各种技术,模仿或利用本机良性软件以隐藏足迹),本文提出了PROV DETECTOR,基于来源检测隐形恶意软件。因为恶意软件会不可避免的和操作系统交互,只需要监控操作的来源就可以检测。首先利用新颖的检测方法来识别可能的恶意行为,然后应用神经嵌入和机器学习方法检测严重偏离正常行为的行为。
概述¶
由于有多种隐藏的方法,基于静态分析的检测方式很难检测隐形恶意软件
利用受信任的和强大的系统管理工具
将恶意代码注入到良性进程
利用良性进程的漏洞获得控制权
由于隐形恶意软件的特性,应该使用防御方法如下
- 检测技术不应该基于静态的文件指示器,因为对于隐形文件系统来说没有区别
- 应该可以检测受信任软件的非预期行为
- 应该轻量级以便获取行为,又不会干扰正常使用
PROV DETECTOR利用内核级别的数据来源监视
两个挑战
检测边缘偏差
模型的可扩展性
主要的攻击方法:代码注入、基于脚本的攻击,漏洞利用
本文检测以下几种
伪装技巧:内存代码注入、基于脚本的攻击和漏洞利用
被用户不小心安装的带有恶意行为的信任应用
定义¶
系统来源图
是一个和进程$p$控制依赖或数据相关的所有实体。$G(p)=<V,E>$,$V$是点集,代表实体,$E$是边集,代表系统事件
相关定义如下

系统事件即关系,关系有一些属性如表
PROVDETECTOR¶
基于异常检测的思想,只检测某个来源图的因果路径子集,这种方法同样解决了路径爆炸的问题并且加速训练。
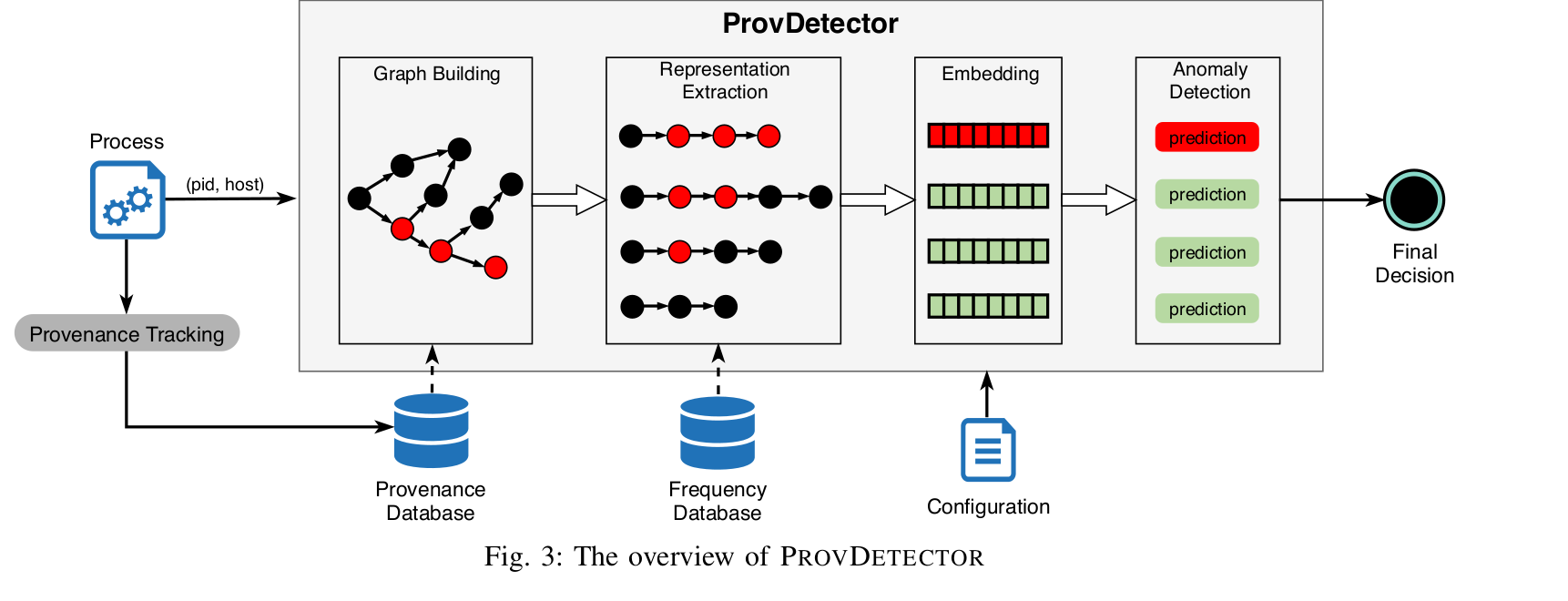
在每一个需要监视的host上安装agent
agent收集数据并存储在中心化的数据库中
定期扫描数据库,确定某个进程是否已经被劫持
首先建立来源图(特征提取)
选择来源图的一个子集并嵌入(向量化)
使用检测器预测每个图是不是被劫持
训练模式下使用向量化后的来源图进行训练
来源图建立¶
即按照上面描述的建立图,定义边$E=\{src,dst,rel,time\}$。源节点只能是进程
首先向点集添加一个点$v=p$
然后找各个关系和其它点如果某个边$e.src\in V\ |\ e.dst\in V$
表征提取¶
由于整个来源图中,大部分都是非恶意的,并且考虑到时间和性能问题,整个来源图并不是个好选择
论文中的方法会过滤一些路径,首先定义一个因果路径$\lambda$,因果路径是一个$G(p)$中系统事件的顺序序列$\{e_1,e_2,...,e_n\}\subseteq G(p), \forall e_i,e_{i+1}\in\lambda$,有$e_i.dst==e_{i+1}.src\wedge e_i.time\lt e_{i+1}.time$,这个约束保证了不会出现循环。对于每一个选择的路径,检测器会移除和host相关或实体相关的特征,例如hostname和pid
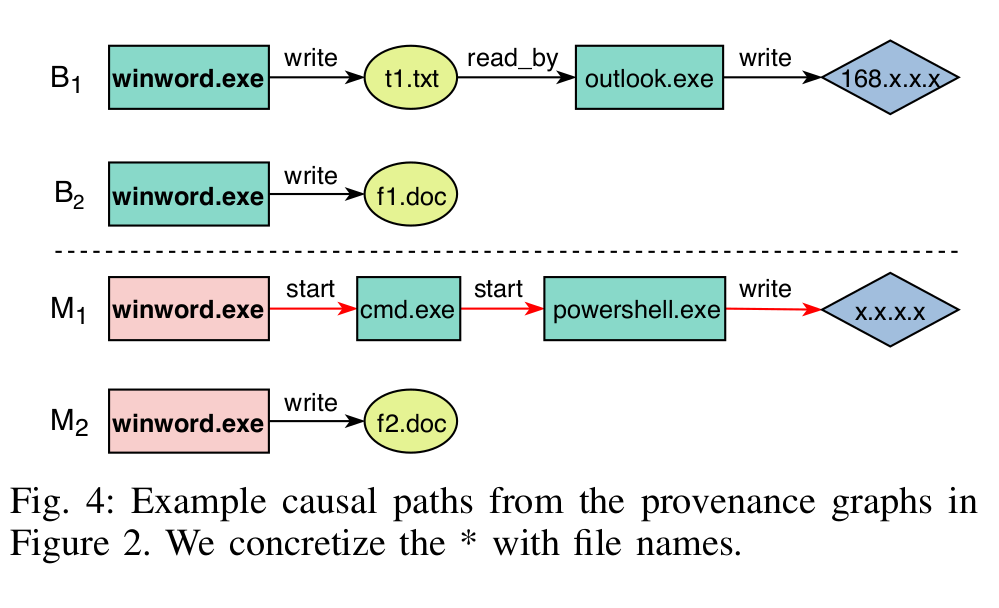
例如图四展示了图二的路径
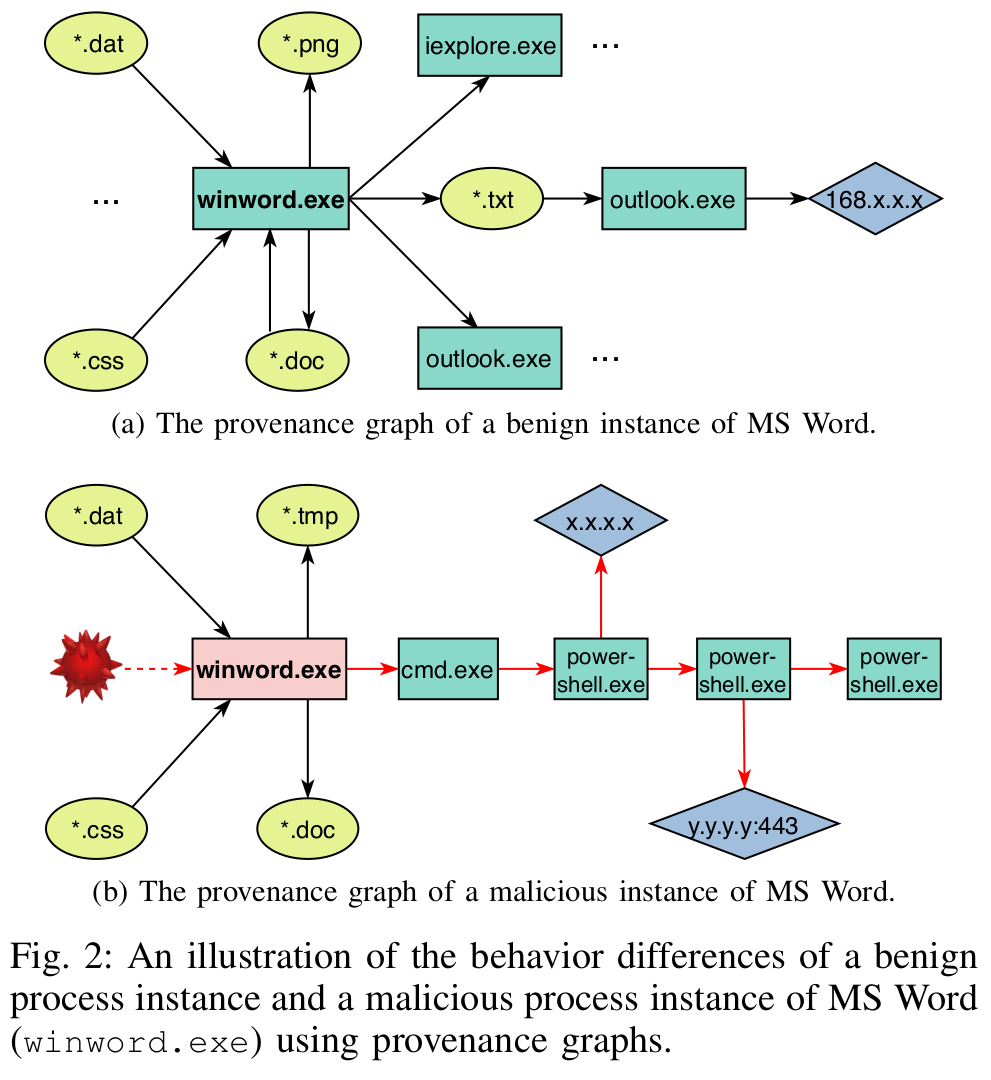
基于稀有度的路径选择¶
由于一个来源图有上千个节点,为了解决路径爆炸的问题,使用基于稀有度的方法选择最稀有的$K$个路径。因为比较广泛的路径一般是正常行为,比如MSword初始化时加载一系列的DLL。
一个路径$\lambda$的稀有度$R(\lambda)=\prod\limits_{i=1}^nR(e_i)$
一个事件$e=\{src\rightarrow dst\}$的正则分数$R(e)=OUT(src)\frac{|H(e)|}{|H|}IN(dst)$
$H(e)$是发生事件$e$的主机集合
$H$是所有主机的集合
要计算$IN$和$OUT$,需要把$v$数据的时间分成$n$个时间窗口$T=\{t_1,t_2,...,t_n\}$
对于每个$t_i$,可以定义如下特点
如果没有新的入边添加到$v$,则这个时间窗口内$v$是输入稳定的
如果没有新的出边添加到$v$,则是输出稳定的
定义
$|T'_{from}|$为输出稳定窗口数量
$|T'_{to}|$为输入稳定窗口数量
则$IN(v)=\frac{|T'_{to}|}{|T|}$,$OUT(v)=\frac{|T'_{from}|}{|T|}$
最稀有的$K$个路径及正则化分数最低的路径,然后转化为最长的$K$个路径
给所有节点添加一个伪源点$v_{source}$和一个伪汇点$v_{sink}$,将图$G$转化为一个单源点单汇点图$G'$,边的长度$W(e)=-log_2R(e)$,$\lambda$的长度$L(\lambda)=\sum_{i=1}^nW(e_i)=-log2\prod_{i=1}^nR(e_i)$,因此$G$中$K$个最稀有的路径即$G'$中$K$个最长的路径
伪汇点的入度和伪源点的出度都被正规化为1
最后再将$G'$转化为有向无环图$G''$,从而使用[Epstein算法][Epstein-Algorithm]解,时间复杂度为线性
嵌入¶
由于NLP中词嵌入比较成熟,将路径转化为句子,例如图4中的B1路径转化为
Process:winword.exe write File:t1.txt read by Process:outlook.exe write Socket:168.x.x.x.
令$l$为将一个节点或边转化为文本表示的函数,则一个路径$\lambda$可以转化为词序列$\{l(e_i.src),l(e_i),l(e_i.dst)|1\lt i\le n\}$
进程节点使用运行路径表示
文件节点使用文件路径表示
socket节点使用源或目的IP端口表示
边使用关系表示
最后使用doc2vec的PV-DM模型嵌入
异常检测¶
来源数据不能使用一个单一的分布模型建模
来源数据有不同的集束,一个程序的工作负载也可以非常不同,很难用一条曲线区分正常和异常数据
使用本地离群点因子法[LOF][LOF],LOF是一个基于密度的算法。如果一个点和它的邻居相比有更小的密度,则判定为离群。
如果$g$中有超过t个向量被判定为恶意的,则判定$g$为恶意的,这里还可以提前终止。
相关资料¶
[Epstein-Algorithm]:D. Eppstein, “Finding the k shortest paths,” SIAM Journal on computing, vol. 28, no. 2, pp. 652–673, 1998.
[LOF]:“Novelty detection with Local Outlier Factor,” https://scikit- learn.org/stable/modules/outlier detection.html#novelty-detection- with-local-outlier-factor, 2019.